Any Dataset or View can be analyzed, using the Relationships button in Explore mode, to:
Each relationship is one or more left-hand columns tested against a single right-hand column within the same table of data. The relationship is said to be a dependency when each left-hand-side values only matches to a single right-hand-side value. Where this does not hold true, the rows with nulls or many right-hand values will be in conflict.
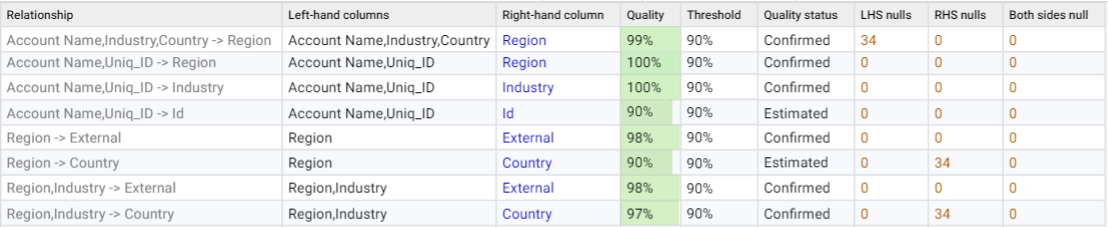
Quality score
The selected columns will all be tested against each other as both the left and right side of the relationship. Each relationship will then be given a Quality score, which is the percentage of rows where the dependency holds.
The quality score is calculated as [(T-C) / T] * 100, where T is the total number of rows and C is the count of the fewest conflicting rows preventing the dependency.
Examples:
Relationship quality threshold (%)
The default value of 98% will return all dependencies and any relationships with few conflicts, which may be worth drilling into to see if there are data quality issues that can be fixed to improve the score. Setting this below 90% will likely return uninteresting and coincidental relationships, which for larger data can also significantly increase the analysis time.
Left-hand columns combined
Up to three columns can be combined automatically on the left side. Selecting Complex analysis will find the best possible quality score, but will increase the analysis time. Unselecting means that if a relationship is found that meets the threshold then no further columns will be added to the left-hand side.
Quality status
A status of 'Estimated' means that the Quality score is close to the relationship quality threshold. Data Studio can determine this quickly without needing to count every single value. This significantly reduces the total time taken to perform the analysis so that focus can be put on the relationships that have the best likelihood of a dependency, which will have a 'Confirmed' status. Estimates are never based on a sample of data and the score is always rounded down. If it is a relationship you are particularly interested in confirming then it is possible to try again with a different threshold value setting.
Once the relationships have been analyzed, any scores lower than 100% indicate that there are rows in conflict. This means that there are multiple different values (including nulls) in the right-hand column against the same left-hand column.
To see what these values are for a specific relationship, select the desired relationship in the data grid and select the Conflicts action (or choose it when right-clicking the row).
The Conflicts drilldown alternates in row colour for each new left-hand side value to better show when moving through different conflicts, and highlights the right-hand column value in blue.
Each conflict has a:
Selecting one or more conflicts enables the Rows action, which will display all the original rows from the data that have that conflict.
