Aperture Data Studio is a high performance self-contained web-based application for data management. It runs on most Java-compliant operating systems on commodity hardware. Data Studio takes full advantage of 64-bit architectures, is multi-threaded and linearly scalable.
View technical recommendations before installation. Note that your setup requirements will depend on the size of your data and Aperture Data Studio usage.
To install Data Studio, download and run the Experian Aperture Data Studio Setup executable.
The installer can be run silently from the command line using the following switches:
Locations for the data folders and the address validation component can be set from the command line using the following parameters:
| Parameter Name | Description | Default folder if not set |
|---|---|---|
| DIRNAME_ROOT | The root database directory. | C:\ApertureDataStudio |
| DIRNAME_DATA | The root variable data file directory. | {DIRNAME_ROOT}\data |
| DIRNAME_IMPORT | The directory used for importing files from the server. | {DIRNAME_DATA}\import |
| DIRNAME_EXPORT | The root directory used for exporting files. | {DIRNAME_DATA}\export |
| DIRNAME_LOG | The log file directory. | {DIRNAME_DATA}\log |
| DIRNAME_RESOURCE | The resources directory. | {DIRNAME_DATA}\resource |
| DIRNAME_REPOSITORY | The directory containing the repository and repository backups. | {DIRNAME_DATA}\repository |
| DIRNAME_TEMP | The temporary files directory. | {DIRNAME_DATA}\temp |
| MATCH_DATABASE_PATH_WINDOWS | The directory for Duplicates stores used by the Find duplicates Workflow step. | {DIRNAME_DATA}\experianmatch |
| SERVER_ADDRESSVALIDATEINSTALLPATH | The Address Validate runtime directory. | C:\ProgramData\Experian\addressValidate\runtime |
| FIND_DUPLICATES_WORKBENCH_PORT | The port for the embedded Find duplicates server. | 26312 |
| GDQ_STANDARDIZE_HOSTNAME | The hostname for the Find duplicates Standardize service. | localhost |
| GDQ_STANDARDIZE_PORT | The port for the Find duplicates Standardize service. | 5000 |
To perform an upgrade the parameter AI_UPGRADE="Yes" can be used.
"Experian Aperture Data Studio 2.3.9 Setup.exe" /exenoui /qn DIRNAME_DATA="C:\DATA" DIRNAME_LOG="C:\LOG"
This will install Data Studio silently, setting the DIRNAME_DATA and DIRNAME_LOG directories.
"Experian Aperture Data Studio 2.3.9 Setup.exe" /exenoui /qn AI_UPGRADE="Yes"
This will upgrade Data Studio from a previous version, using the same configuration settings. To not migrate the existing configurations, use the option MIGRATE_APPLICATION=”False” alongside your upgrade parameter. "Experian Aperture Data Studio 2.3.9 Setup.exe" /exenoui /qn AI_UPGRADE="Yes" MIGRATE_APPLICATION="False"
When the installation is complete:
http://localhost:7701/ or use the shortcut on your desktop. Note that it may take a minute for the service to start.By default, the amount of memory Data Studio can use (more accurately, the initial and maximum heap size) is set at runtime based on system configuration. In most cases, this is suitable for both development and production instances.
In come scenarios you many want to modify memory settings to optimize the resources available and to obtain consistent behavior. Memory settings may need to be further tuned based on the results observed once in use with the production data, users and regular workload.
We recommend that no more than 50% of the available RAM on the server is dedicated to Data Studio. Using more may impact the performance and stability by restricting resources available for the operating system and file system cache.
To add custom memory settings, edit the Aperture Data Studio Service 64bit.ini file in the installation directory. Use the Virtual Machine Parameters setting to modify memory settings. For example, to set both the initial and the maximum heap to 32GB, add the following arguments at the end of the Virtual Machine Parameters line: -Xms32G -Xmx32G. The result will be similar to:
Virtual Machine Parameters=-XX:+UseG1GC -XX:+UseStringDeduplication -Djavax.net.ssl.trustStore="C:\ApertureDataStudio\certificates\cacerts" -Xms32G -Xmx32G
Where -Xms is the minimum amount of heap space the process will use, -Xmx is the maximum. These are followed by the amount of memory to be used as a whole integer and either M or G. M is megabytes and G is gigabytes.
The Data Studio service will need to be restarted after these changes are made.
The metadata repository is the main underlying database that stores all information in Data Studio other than the actual data being processed. This includes users, environments, workflows, functions, datasets (only the metadata not the data itself) and views.
The repository is a SQLite relational database which stores the metadata information for all environments in your Data Studio instance. This consists of a single file, the repository.db, located in the \data\repository folder in the database root directory.
Backups of this repository are configured by modifying the repositories.json file which can be found in the installation root directory.
The default file will look as follows:
[ {
"id" : "5f3b8528-49d5-4a05-802e-c5437468126b",
"name" : "Default",
"datastoreType" : "SQLITE",
"directory" : "C:\\ApertureDataStudio\\data\\repository",
"filename" : "repository.db",
"backupOptions" : {
"enabled" : false,
"intervalInMinutes" : 2,
"backupHistoryIntervalInMinutes" : 1440,
"maxHistoricBackups" : 7,
"backupOnStartup" : true
}
} ]
To configure backups, change the "enabled" setting to true.
"enabled" : true,
The Data Studio service will need to be restarted after these changes are made.
When backups are enabled, two levels of backup will be created.
intervalInMinutes and will be placed in a file called repository-backup.db alongside the original repository.backupHistoryIntervalInMinutes and placed into a backup folder within the repository folder. The default is to backup once a day. The most recent historical backup will be named repository-backup-current.db.When replicating for disaster recovery it is safe to backup the files within the \repository\backup folder. The active repository.db and repository-backup.db files should not be copied as they are being actively written to.
Log4j 2 can be configured using the log4j2.xml file found in your installation directory.
The logging configuration file is made up of two main sections. Appenders define where log information is written to.
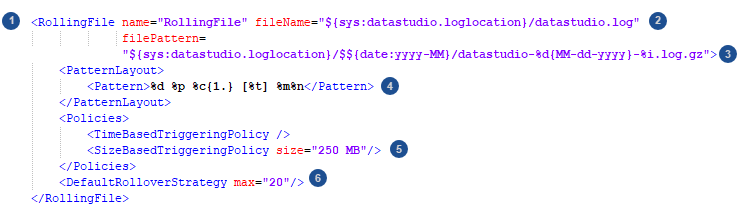
The Logger section defines what information gets written.
The log levels available to use are trace, debug, info, warn or error. The default log configuration is set to log informational level events, however this should be raised to warning or error in production to avoid large log files.
Find duplicates also uses Log4j 2 for logging. The log4j2.xml file can be found in the Tomcat webapps directory Tomcat x.x/webapps/match-rest-api-x.x.x/WEB-INF/classes.
By default Find duplicates is configured to log error messages only, apart from the following cases.

By default the Data Studio server serves on port 7701 and includes a self-signed certificate to support secure HTTPS connections.
In many cases a certificate signed by a trusted certificate authority (CA) should be applied to the server to enable encryption of client-server communications and appropriately identify your server to clients.
To add an SSL certificate to the keystore and configure Data Studio to use the default HTTPS port (443):
.pem or .key file). .pem or .crt file). If you have root and intermediate certificates in separate files, combine these first. Server certificate and Public certificate uploads
The Data Studio database is made up of a number of different folders, which by default are all located under the database root directory.
Most of the database folder locations can be configured during installation. To change them after installation time:
Navigate to the installation folder (by default C:\Program Files\Experian\Aperture Data Studio {version}) and open the server.properties file.
On a new line in the file, add the setting you want to modify:
| Setting name | Default value | Description |
|---|---|---|
DirName.ROOT |
C:/ApertureDataStudio | |
DirName.DATA |
%ROOT%/data | |
DirName.REPOSITORY |
%DATA%/repository | Contains the metadata repository, and backups if backup is configured. |
DirName.IMPORT |
%ROOT%/import | Contains files that can be loaded from the server's import directory. Files in sub-folders will be available. |
DirName.EXPORT |
%DATA%/export | Contains files exported to the server's export directory. |
DirName.LOG |
%DATA%/log | Contains server log files. |
DirName.TEMP |
%DATA%/temp | Contains temporary files. |
DirName.TEMP_WORKFLOWREPORT |
%TEMP%/workflowreport | Contains temporary files. |
DirName.TEMP_FILEUPLOADS |
%TEMP%/fileuploads | Contains temporary files. |
DirName.CACHE |
%DATA%/cache | Contains caches generated by workflow steps. |
DirName.CACHE_STEP |
%CACHE%/step | Contains caches generated by custom workflow steps. |
DirName.RESOURCE |
%DATA%/resource | Contains all loaded data and indexes created during workflow execution indexes or during interactive data exploration. |
DirName.DRIVERS_JDBC |
%ROOT%/drivers/jdbc | The location of JDBC drivers used for External System connections. |
Dataset.dropzone |
%DATA%/datasetdropzone | Contains dataset-specific file dropzones. |
For example, to change the location of the database root directory to the D:\ drive, the entry in server.properties should be:
DirName.ROOT=D:\\aperturedatastudio
To change the location of the export directory to a network location using the UNC path, the setting should be similar to:
DirName.EXPORT=\\\\myfileserver.myorg.local\\datastudio\\fileexports
If you're changing DirName.ROOT, DirName.DATA or DirName.REPOSITORY you need to ensure that the path to the repository.db file is also changed in the repository.json file. This file is located in the same folder as the server.properties file.
To configure Data Studio to write to a network drive, use the full UNC path and make sure that the account running the Data Studio Database Service (by default the Local System account) has write access to the network drive folder location. Only DirName.IMPORT, DirName.EXPORT and Dataset.dropzone are suitable options for network locations.
The Data Studio service will need to be restarted for changes to take effect.
To encrypt Data Studio resources at-rest on the storage medium:
Resources are files that can be found in the 'data/resource' folder. They can be loaded Datasets, Snapshots or caches for some of the Workflow steps (e.g. Address validate). Any resources that could possibly
contain PII data will be encrypted using AES256/GCM and a randomly generated key. The key is itself encrypted and stored in the built-in Aperture Data Studio vault.
For performing domain level validation of email addresses using Data Studio's Validate Emails step, the location of an accessible Domain Name System (DNS) server should be configured.
The default server used is 8.8.8.8, the Google DNS, but network or firewall configuration settings may prevent you from accessing this IP address for DNS.
To check if the default Google DNS server is accessible from the Data Studio server, open a command line console and run:
nslookup experian.com 8.8.8.8
If this is successful, the command will return:
Server: dns.google
Address: 8.8.8.8
Non-authoritative answer:
Name: experian.com
If the DNS server is not accessible, the command will report DNS request timed out. In this case:
ipconfig /all from the command line on the server Data Studio is installed on should return IP addresses for DNS servers that can be accessed.Aperture Data Studio supports LDAP (Lightweight Directory Access Protocol) and SAML (Security Assertion Markup Language) for SSO (single sign-on) authentication.
If you want to configure Data Studio to use one of these methods of above, instead of Data Studio's own internal username/password method, select one of the options above to find out more.
Before creating any users, you should ensure that the password policy and other security settings enforced by Data Studio meet your security requirements.
To view and change the settings, Browse to Settings > Security:
If installing Find duplicates in a system for processing more than 1 million records, we strongly recommend following these steps to deploy the Find duplicates server onto a separate instance from Data Studio.
In cases where Find duplicates will not handle large volumes, the Find duplicates server that's embedded with Data Studio can be used, and no separate installation is needed.
If you are licensed for postal address validation, follow these steps to configure Validate addresses.
